Mapping Hidden Code Wisdom: Meta's AI Strategy for Tribal Knowledge
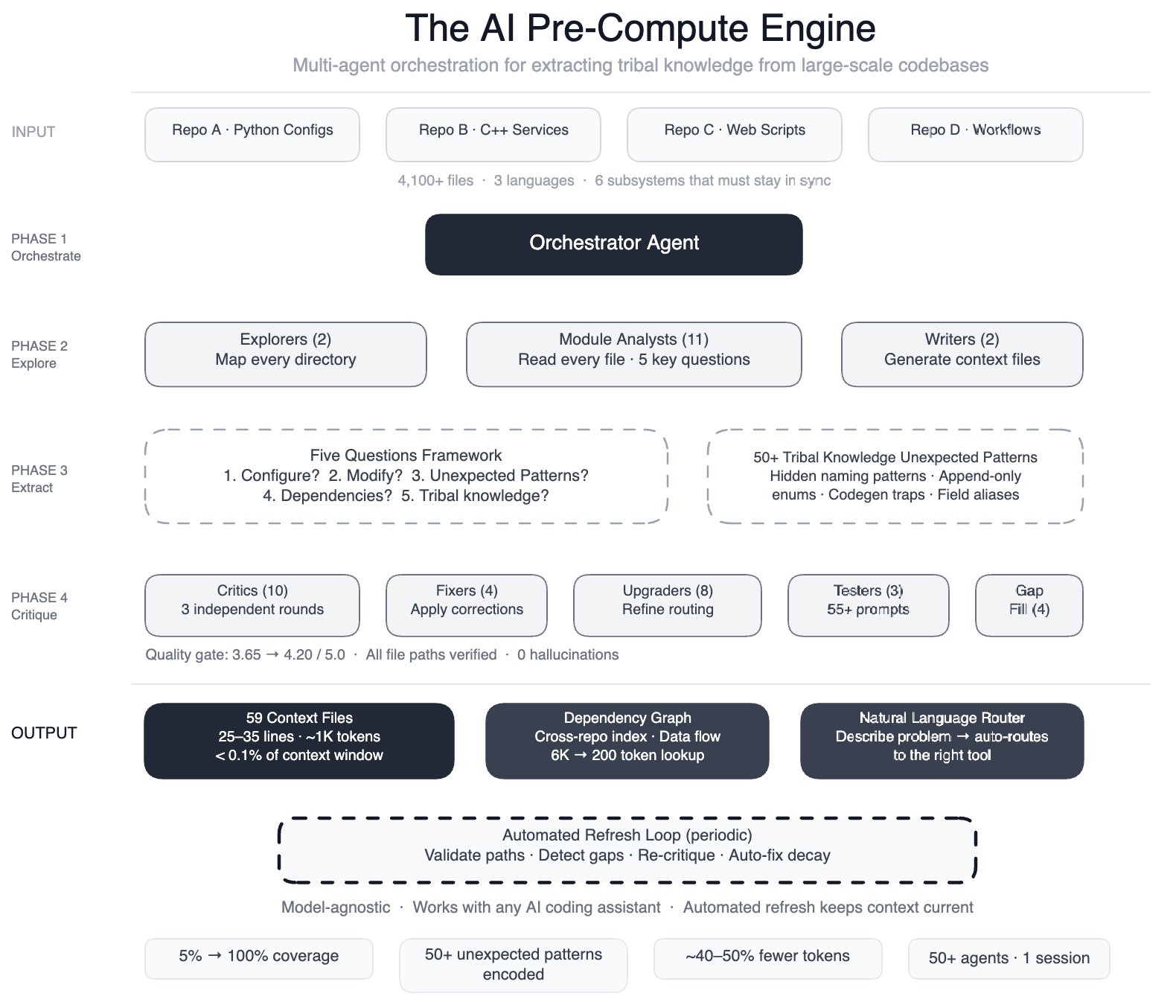
In the world of large-scale software engineering, much of the essential knowledge about how systems truly work resides not in code comments or documentation, but in the minds of experienced engineers. Meta faced this challenge head-on when deploying AI coding assistants on a massive data processing pipeline spanning four repositories, three programming languages, and over 4,100 files. The AI agents lacked a map of the codebase's unwritten rules and subtle interdependencies, leading to inefficient edits and subtle bugs. This article explores how Meta engineered a solution using a swarm of specialized AI agents to extract and encode tribal knowledge, dramatically improving agent performance and maintainability.
What specific problems did Meta encounter when using AI agents on their data pipeline?
Meta's data pipeline was a complex beast: Python configurations, C++ services, and Hack automation scripts all worked together across multiple repositories. A single task like onboarding a data field touched six subsystems that had to stay perfectly in sync: configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts. When Meta pointed AI coding assistants at this pipeline, the agents had no understanding of the hidden relationships. For example, two configuration modes used different field names for the same operation, and swapping them produced silent wrong output. Dozens of “deprecated” enum values could never be removed because serialization compatibility depended on them. Without this context, AI agents would guess, explore, and often produce code that compiled but was subtly incorrect. The result was that agents couldn't make useful edits quickly enough, undermining their value for development tasks.

How did Meta approach teaching AI agents about the codebase's tribal knowledge?
Instead of trying to embed all knowledge into the AI model itself, Meta built a pre-compute engine: a swarm of 50+ specialized AI agents that systematically read every file and produced concise context files. The approach was structured in phases using a large-context-window model and task orchestration. First, two explorer agents mapped the entire codebase. Then 11 module analysts read every file and answered five key questions about each module. Two writers generated 59 context files that captured the tribal knowledge previously locked in engineers' heads. Ten or more critic passes ran three rounds of independent quality review, with four fixers applying corrections. Eight upgraders refined the routing layer, three prompt testers validated over 55 queries across five personas, and four gap-fillers covered remaining directories. Finally, three final critics ran integration tests. This orchestration turned the AI from a passive consumer into an active engine for knowledge extraction.
What were the key results of this tribal knowledge mapping effort?
The results were striking. AI agents now have structured navigation guides for 100% of Meta's code modules, up from just 5% coverage. All 4,100+ files across three repositories are now documented in 59 context files that encode design decisions and non-obvious patterns. The team documented over 50 “non-obvious patterns” — underlying design choices and relationships not immediately apparent from the code itself. In preliminary tests, AI agents made 40% fewer tool calls per task because they no longer needed to explore blindly. The knowledge layer is model-agnostic, meaning it works with most leading AI models. Perhaps most importantly, the system maintains itself: every few weeks, automated jobs validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. The AI isn't just a consumer of this infrastructure — it's the engine that keeps it running.
How does the self-maintenance of the knowledge system work?
Meta recognized that codebases evolve, so their knowledge mapping couldn't be a one-time effort. They built automated jobs that run every few weeks to keep the context files fresh. These jobs periodically validate file paths to ensure all references are still correct, detect coverage gaps where new modules may have been added without documentation, re-run quality critics to score the context files against current code, and auto-fix stale references. This means the system is self-sustaining — engineers don't need to manually update the knowledge base. The AI that extracts the knowledge also maintains it. This approach ensures that the tribal knowledge captured in the 59 context files remains accurate over time, even as the pipeline grows and changes. It's a clever loop: AI created the map, and AI keeps the map up to date, freeing human engineers from a tedious but critical maintenance task.
Why is the knowledge layer model-agnostic and why does that matter?
The context files produced by Meta's swarm of AI agents are stored in a model-agnostic format. This means they can be consumed by any large language model, not just the specific model used during the extraction process. The system works with most leading AI models because the knowledge is structured as plain-text or structured files that any model can read. This is a crucial design choice for several reasons. First, it future-proofs the system: as new and better models emerge, Meta can simply point them at the same context files without rebuilding the knowledge base. Second, it avoids vendor lock-in to a specific AI provider. Third, it allows different teams within Meta to use their preferred AI tools while still benefiting from the same rich, shared understanding of the codebase. The knowledge layer becomes a reusable asset, separate from any particular AI implementation.
What specific types of tribal knowledge did the AI agents uncover?
The 59 context files and 50+ documented patterns reveal several categories of hidden knowledge. One critical type is silent-breaking changes: situations where swapping parameters or field names compiles fine but produces incorrect output. Another is serialization constraints: enum values that appear deprecated but must never be removed because serialization compatibility depends on them. The agents also uncovered cross-repository dependencies — how a change in one language's configuration affects services written in another language. Third was non-obvious ordering rules: for example, the sequence in which validation rules must be applied to avoid race conditions. Fourth were implicit conventions like naming patterns that signal whether a function is safe to call in production. By systematically reading every file and answering five key questions per module, the analysts extracted knowledge that was previously only in engineers' heads – and often not written down anywhere.
How did the orchestration of 50+ specialized AI agents work in practice?
Meta orchestrated the work using a large-context-window model to coordinate a swarm of specialized agents. The orchestration was structured like a production pipeline, not a single monolithic AI. It began with two explorer agents that mapped the codebase to understand its structure. Then 11 module analysts each read files and answered five key questions about each module's purpose, interfaces, dependencies, risks, and patterns. Two writers synthesized the answers into 59 context files. The quality assurance was rigorous: 10+ critic passes ran three independent rounds of review, with fixers applying corrections. Eight upgraders refined the routing layer to ensure context files pointed to the right code. Then three prompt testers validated how well the context files worked for 55+ queries across five different user personas. Four gap-fillers covered remaining directories, and three final critics ran integration tests. In total, 50+ specialized tasks were orchestrated in a single session, demonstrating how AI can be the engine that runs complex infrastructure – not just a consumer of it.