From Hand-Tuning to Autonomous Search: Meta’s KernelEvolve Agent Transforms AI Infrastructure Optimization
Introduction
Meta operates a massive fleet of AI models that power billions of daily user interactions, from personalized recommendations to generative AI assistants. Behind these experiences lies a complex infrastructure of heterogeneous hardware, including NVIDIA GPUs, AMD GPUs, Meta's custom MTIA silicon chips, and CPUs. To maximize performance, every model operation must be translated into highly efficient, chip-specific kernels—the low-level code that runs on each accelerator. Traditionally, writing and optimizing these kernels required months of manual effort by expert engineers. But with the introduction of KernelEvolve, an autonomous agent built into Meta’s Ranking Engineer Agent, that process is now being transformed into a fast, scalable, and automated search.
The Challenge of Heterogeneous Hardware
Why Manual Kernel Optimization Doesn’t Scale
As new chip generations and ML model architectures emerge, each combination demands custom kernel code. Vendor libraries like cuBLAS cover standard operators (GEMMs, convolutions), but production workloads often require dozens of custom operators—especially in ranking models. With the number of models multiplying across hardware types and generations, hand-tuning by kernel experts simply cannot keep pace. A single kernel optimization can take weeks of profiling, debugging, and iterative refinement, leaving engineers with little time for higher-level innovation.
Introducing KernelEvolve: An Agentic Kernel Authoring System
Treating Optimization as a Search Problem
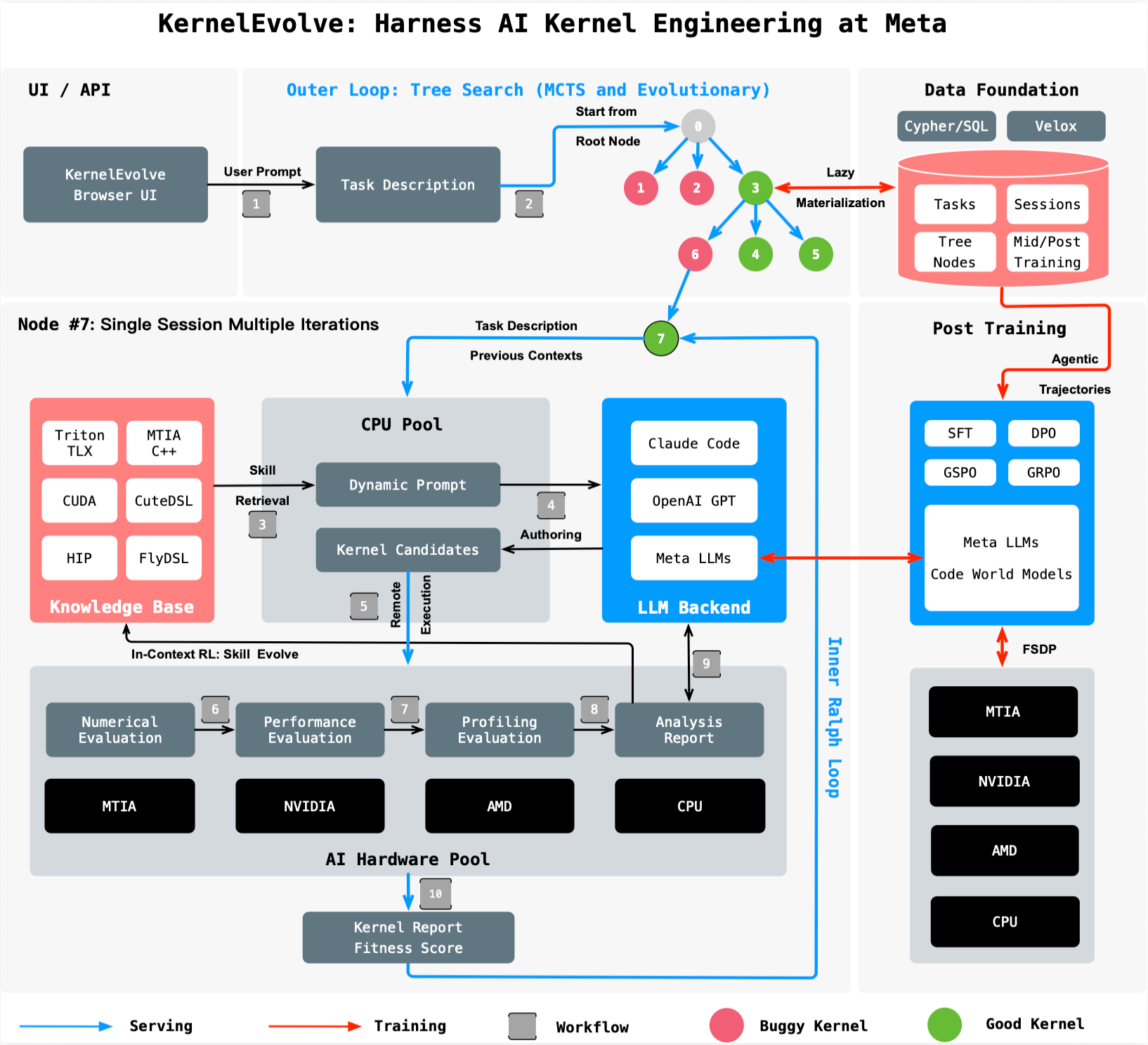
KernelEvolve reframes kernel optimization as a search problem. A purpose-built job harness evaluates each candidate kernel, feeds detailed diagnostics back to a large language model (LLM), and drives a continuous search over hundreds to thousands of alternatives. This agentic approach replaces the linear, expert-driven process with an autonomous loop that can explore far more design variations in a fraction of the time. The result: kernels that often exceed the performance of manually crafted versions.
Integration with the Ranking Engineer Agent
KernelEvolve is a core component of Meta’s Ranking Engineer Agent, which autonomously designs, executes, and analyzes ranking model experiments. While the agent’s ML exploration capability handles high-level model changes, KernelEvolve optimizes the underlying infrastructure—ensuring that those models run efficiently at scale. This dual-layer autonomy accelerates the entire innovation pipeline, from experiment ideation to production deployment.
Proven Performance Gains
Real-world deployments of KernelEvolve demonstrate dramatic improvements:
- Faster development: Weeks of expert engineering time are compressed into hours of automated search, freeing engineers for creative problem-solving.
- Better performance: The Andromeda Ads model saw a 60% inference throughput improvement on NVIDIA GPUs, and an ads model achieved a 25% training throughput gain on Meta’s custom MTIA silicon chips.
- Broad applicability: KernelEvolve optimizes across public and proprietary hardware, generating kernels in high-level DSLs like Triton, Cute DSL, and FlyDSL, as well as low-level languages including CUDA, HIP, and MTIA C++.
These gains are a direct result of the agent’s ability to explore a larger design space than any human could manually cover within the same time window.
Broad Applicability Across Hardware and Languages
KernelEvolve is not limited to ranking models or any single hardware platform. It has been tested and validated on NVIDIA GPUs, AMD GPUs, Meta’s MTIA chips, and standard CPUs. The agent automatically adapts its search to the target architecture and can output code in both high-level domain-specific languages and low-level native languages. This flexibility makes it a general-purpose tool for any AI team grappling with heterogeneous infrastructure, not just Meta’s Ads group.
Future Directions and Research
The kernel optimization work described here is detailed in the paper “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta”, to be presented at the 53rd International Symposium on Computer Architecture (ISCA) 2026. Ongoing research focuses on extending the agent to handle multi-device orchestration, dynamic kernel selection at runtime, and integration with Meta’s wider AI infrastructure management. As AI models grow in complexity and hardware diversity increases, autonomous agents like KernelEvolve will become indispensable for maintaining peak performance.